Computer Architecture - Performance
Performance에 대해 설명하기 전, Parallelism과 RISC, CISC 개념을 확인해 보자
Parallelism에는 여러 종류가 존재한다.
- Instruction Level Parallelism(ILP)
- Data Level Parallelism(DLP)
- Task Level Parallelism(TLP)
1. Instruction Level Parallelism(ILP)
ILP의 경우에는 쉽게 말해 명령어를 동시에 수행한다라고 볼 수 있다.
-Pipelining
-Superscalar
- OoO(Out of Order) Execution
- Branch Prediction
- VLIW(Very Long Instruction Word)
등이 예시이다.
2. Data Level Parallelism(DLP)
DLP는 여러 데이터 요소에 대해 동일한 작업을 병렬로 수행하는 것이다
- SIMD(Single Instruction Multiple Data) / Vector Instructions
대표적인 예시라고 할 수 있다.
3. Task Level Parallelism(TLP)
TLP는 여러 개의 코어를 가지고 각각의 코어에서 처리하는 것이라 볼 수 있다.
- Simultaneous Multithreading (Hyperthreading)
-Multicore
등이 대표적인 예시라 할 수 있다.
CISC VS. RISC
RISC(Reduced Instruction Set Computer)
- 하나의 명령어가 상대적으로 간단하다.
-Clock Cycle 하나당 하나의 instruction을 수행한다.
-HW 구조가 덜 복잡하다.
CISC(Complicated Instruction Set Computer)
- 하나의 명령어가 여러 실행을 수행한다.
- 명령어 하나가 상대적으로 복잡하다
- 따라서 명령어 하나를 처리하는데 여러 Clock Cycle이 걸린다.
Performance를 측정할 때 기준은 뭘까? 어떤 지표로 평가해야 할까?

Computer에서 대부분의 Metrics의 경우 시간과 관련되어 있는 것을 알 수 있다 (How Fast)
즉 CPU performance를 측정할 때 execution time과 관련이 높음 (execution time ↓ , performance ↑)
(성능이 올랐다 == 수행시간이 줄었다)
그리고 이러한 digital system의 경우에는 clock cycle 단위로 동작을 한다.
-Clock Rate(a.k.a Clock Frequency, Clock Speed): 1초에 Clock Cycle이 몇 개 있는가(= 1 / Clock Cycle time)
-unit: Hz or MHz or GHz
그렇다면 이런 Clock Cycle time은 어떻게 결정하는 것인가?
-Critical path delay(Longest propagation delay): 수많은 combinational paths 중에서 가장 긴 timing delays를 가지는 path(Critical path)에서의 dealy를 의미한다.
따라서 Clock Cycle time의 경우에는 이런 Critical path를 기준으로 결정되는 것이다.
결론적으로
Excution Time = # of Instructions * CPI(Cycle Per Instruction) * Clock cycle time
또는 Excution Time = Clock cycles for program / Clock rate로 표현할 수 있다.
따라서 Excution Time을 줄이기 위해서는 아래의 방법을 사용할 수 있다.
1. Clock rate를 늘린다.(= Clock Cycle Time을 줄인다)
2. CPI를 줄인다. (ISAs에 따라 CPI가 달라짐)
3. # of instruction(total instruction 수)를 줄인다.
하지만 같은 Processor여도 Instruction Type에 따라 필요 Cycle 수가 다르다.
예를 들어서
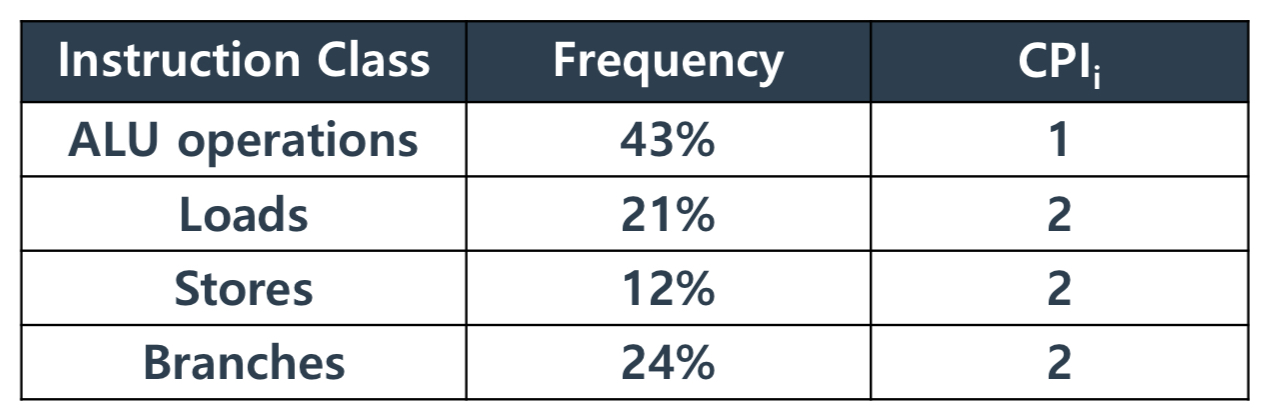
해당 Table 처럼 program의 instruction이 구성되어 있다면
평균 CPI = 0.43 x 1 + 0.21 x 2 + 0.12 x 2 + 0.24 x 2 = 1.57
따라서 total Clock Cycle = 1.57 * instruction Count 인 것이다.
CPI를 제외한 다른 Performance Metrics
MIPS(Million Instruction Per Second)
- MIPS = Instruction Count / (Execution Time x 10^6)
MIPS를 사용할 경우 1초에 몇 개의 명령어 연산을 하는지 직관적으로 볼 수 있다.
-GFLOPS(GIGA Floating-point operation per second)
-TFLOPS(TERA Floating-point operation per second)
FLOPS의 경우 Instruction 보다 operation에 중심을 둔 Performance Metrics이다.
- e.g., floating-point addition, multiplication etc..
하지만 CPI가 낮다고, MIPS가 높다고 항상 성능이 좋다고 할 수 있는 것은 아니다.
CPI가 낮지만 Clock rate(Clock frequency)가 작을 경우 성능이 나쁠 수 있고
MIPS의 경우에도 MIPS가 더 크지만 Execution Time이 더 길 수 있는 것이다.