- Introduction
- CXL 기술은 Cost - effective 한 memory expansion 기술임
- 하지만 아무리 memory bound application 이라고 해도 Latency sensitive application, bandwidth-sensitive application 따라 성능 하락이 발생함
- Local memory에 비해 Latency, bandwidth 모두 부족하기 때문이다.
- 이러한 문제의 해결책으로 NDP를 사용하고 있지만 Domain-Specific NDP HW logic의 경우 Target-workload를 제한하는 문제가 발생
- 그리고 이런 special-purpose NDP HW의 경우 total area도 높고, NRE(Non-recurring engineering, 제품을 생산하는데 들어가는 초기 비용)또한 높기 때문에 Practical하지 못함
본 논문에서 말하는 핵심은 GPNDP(General Purpose NDP)가 CPU, GPU cores를 NDP unit으로 사용했을 때 보다 효율적인지, 얼마나 효율적인지를 보여주는 내용임
그리고 그러한 GPNDP를 구현하기 위해 사용된 Memory-Mapped NDP (M^2NDP)를 어떤 방법으로 구현했는지에 대해 말하고 있다.
- CXL Background
CXL은 PCIe의 PHY Layer를 사용하고 3가지 프로토콜을 사용함
CXL.io
-기존 PCIe protocol과 똑같이 동작, device management를 담당
CXL.mem
-memory expansion을 가능하게 했고, 간단하게 load/store 명령을 발행하는 것으로 access 가능
CXL.cache
-host와 device 간 cache coherence를 위한 protocol
즉 CXL.io( = PCIe protocol) 인 것이고 그러다 보니 ~ 1µs 까지 느리고
반대로 CXL.mem의 경우 간단한 load/store 명령 발행으로 가능하니 ~70ns 까지 가능함
즉 CXL.mem protocol을 활용하는 것이 중요

그리고 HDM(Host Device Memory)의 경우 HDM-H(Host only coherent), HDM-DB(Device coherent using back-invalidation) 두가지 모델 중 하나를 사용함
말 그대로
HDM-H(Host only coherent)
- host만이 수정 가능함 host에게만 coherent가 보장되는 것
HDM-DB(Device coherent using back-invalidation)
- device 가 snoop filter를 통해 host의 caching을 tracking 하고 필요시에 back-invalidation을 통해 최신 data를 사용하게 한다.
CXL Device에서 local memory로 access 하고 싶은 경우 그냥 할 수 없음
먼저 address translation 과정을 거쳐야 함 그것이 Address Translation Services (ATS) 임
하지만 이 경우 µs - sacle의 latency가 발생함 (protocol overhead + page table 보는 overhead )
따라서 이를 줄이기 위해 Address Translation Cache (ATS)를 추가해 최근에 Translation 한 내용을 cache에 저장하고 빠르게 참조하는 것임
하지만 incorrect tranlation인 경우가 발생할 수 있음( e.g. 기존 page에서 migration 한다던지 등등) 그런 경우에는 device의 ATC를 invalidate 처리할 수 있음
M2func - Memory Mapped function
본 논문에서 주장하는 두가지 기능 중 한가지 이다.
Memory Map 방식으로 function call을 하는 방법으로 NDP 에서 kernel 구동을 빠르게 진행하는것이 핵심이다.
일단 이 M2func이 나오게 된 배경, 즉 문제상황을 알면 좋을 것 같다.
1. 기존 i/o 통신 방식 중 CXL.io(= PCIe통신) ring buffer 방식은 round-trip latency가 너무 길다. (3~6µs)
2. DMA 방식을 사용하더라도 kernel launch하는데 2.5번의 round-trip latency가 발생함 (~1µs)
3. 즉 결론적으로 해당 latency는 latency-sensitive application에는 좋지 못함
4. device register를 사용하는 MMIO 방식을 통해 해당 overhead를 줄일 수 있지만 해당 방법의 경우 multiple concurrent request를 수행하지 못함 (device register의 경우 물리적 자원이기 때문에 overwritten 될 수 있음)
5. 따라서 해당 과정을 피하기 위해(device register관리를 kernel이 해야하기 때문) usermode에서 kernelmode로 전환되는 context switching 과정이 요구되고 해당 과정의 overhead 또한 문제가 됨
따라서,
protocol stack, ring buffer management, and context switch to the OS이런 문제들 때문에 CXL.io protocol이 CXL.mem 에 비해 latency가 길다는것을 위해 만들어 졌다.
(low latency를 위함)
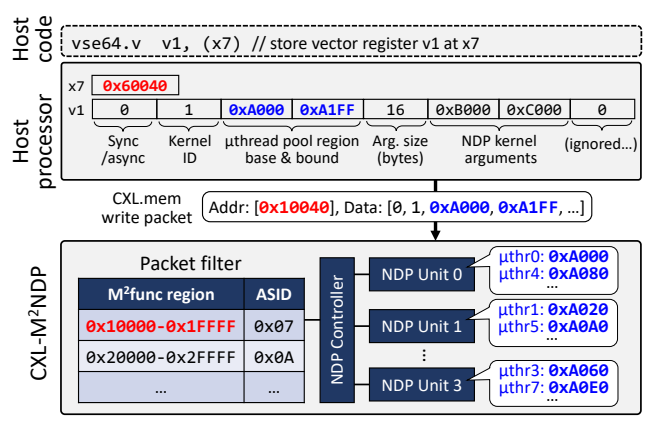
M2func기능
M2func의 기능
1. packet filter를 통해 M2func 을 통한 function call을 할지, 기존 CXL.mem 을 사용할지 Packet filter를 통해 확인
장점: M2func만 쓰는 것이 아닌 기존 CXL.mem 또한 문제없이 사용할 수 있음 + packet filter를 만드는데 64-bit base, 64-bit bound, and 16-bit ASID 즉 18B 만 필요함 Overhead 적음
2. CXL.mem protocol의 장점인 간단한 read/wirte instruction 만으로 다양한 function call이 가능해짐
장점: 매우 빠른 access로 function call이 가능해짐(e.g. kernel 등록 etc..) 즉 kernel mode 전환이 필요 없어짐
3. 정확하지 않지만, 해당 M2func 은 concurrently하게 kerenl실행이 가능함 prior work에서 하던 CXL.io 기반 MMIO의 경우에는 불가능 했음(physical device register의 overwritten문제 때문) M2func 가능한 이유는 MMIO가 아니라 Memory Map방식으로 function call을 하는 것이기 때문에 물리적인 레지스터에 overwritten 되는 것을 고려할 필요가 없는 것이라고 생각
+ 애초에 device 접근이 아니라 NDP Unit에서 function 실행하는거라 device register 고러하지 않아도 되는 것일수도

API for M2NDP
해당 API를 호출하면 커널 등록하고 실행하고 하는거임
Base address에서 offset이 얼마만큼 떨어져 있느냐에 따라 어떤 API가 실행되는지 결정하는 방법인 것임
Arguments와 return value를 충분히 수용할 수 있어야 하므로 offset이 넉넉해야함
본 설명에서는 1<<5 32B를 예시로 잡음
위에서부터 차례대로
0 ~ 32B
~ 64B
~ 96B
~ 128B
범위에 들어가면 알맞게 Function call이 되는 것임
예외적으로 Kernel 길이 가 매우 긴 Kernel이 존재할 수 있음 이러한 경우 CXL.mem 으로 해결할 수 없음
따라서 이러한 경우에도 동작을 보장하기 위해 CXL.io protocol로도 동작할 수 있게 configuration 해놓음
OS에서 부팅할 때 CXL.mem + M2func mode로 동작할 것인지, CXL.io Mode로 동작할 것인지 선택할 수 있음
+ high level 에서 programming 됐기 때문에 user가 사용할 때 low level의 동작 원리를 이해하면서 code를 짤 필요는 없음
M2µthread (Memory-Mapped µthreading)
M2µthread 등장 배경, 문제상황
1. CPU의 경우 ISA에 따라 다르지만 Thread 실행시킬때 모든 register file을 사용함(사용하지 않는 register 존재 가능)
2. GPU에서 Thread address 계산 시에 SIMT에서 scalar instruction의 부족으로 불필요한 연산이 발생함
3. intra-warp divergence(사진 참고) 발생으로 TB(Thread Block)내에 idle 상태인 warp이 성능 하락을 유발함
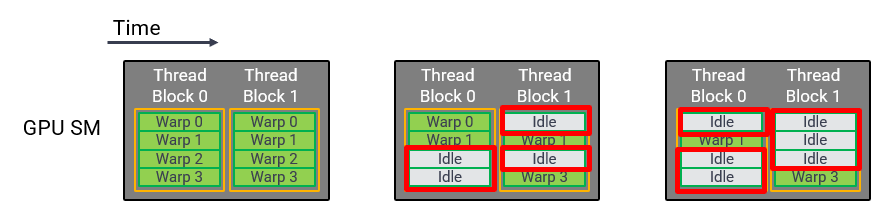
따라서 M2µthread 기능을 주장함
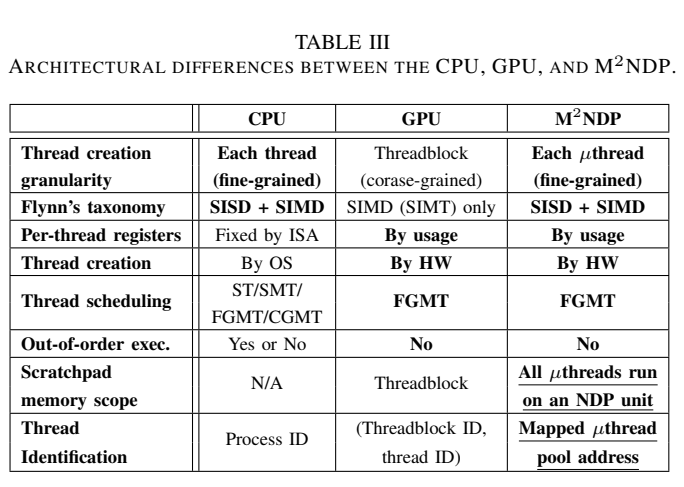
그림에서 보이는 것 처럼
GPU와 유사한 Architecture를 가지는 것 같음
CPU의 경우 ISA에 의한 Fixed size register를 가지지만 GPU와 M2NDP는 By usage 인 것
µthread가 일정한 단위로 묶여서 bulk synchronous parallel manner 으로 동기화 함(= warp 단위로 동작하는 것과 유사하다고 볼 수 있음)
그렇다면 차이점이 무엇인지 확인해보자
1. address calculation overhead가 감소함 µthread pool region 으로 mapping되는 방식이기 때문에 기존 GPU에서 Thread index 등 address를 계산하는 overhead가 감소함
2. per-thread register를 by usage하게 할당하기 때문에 더 적은 register file를 사용하고, Area overhead가 적어짐
3. inter-warp divergence에 의한 resource fragmentation and underutilization을 방지하고 thread마다의 irregular workloads에 의해 발생하던 성능 하락을 방지함(어차피 µthread 단위로 처리하기 때문에 idle 상태를 최소화)

4. 이건 결국 GPU에서 사용하는 threadblock hierarchy를 없애버렸기 때문에 얻을 수 있었던 이점임
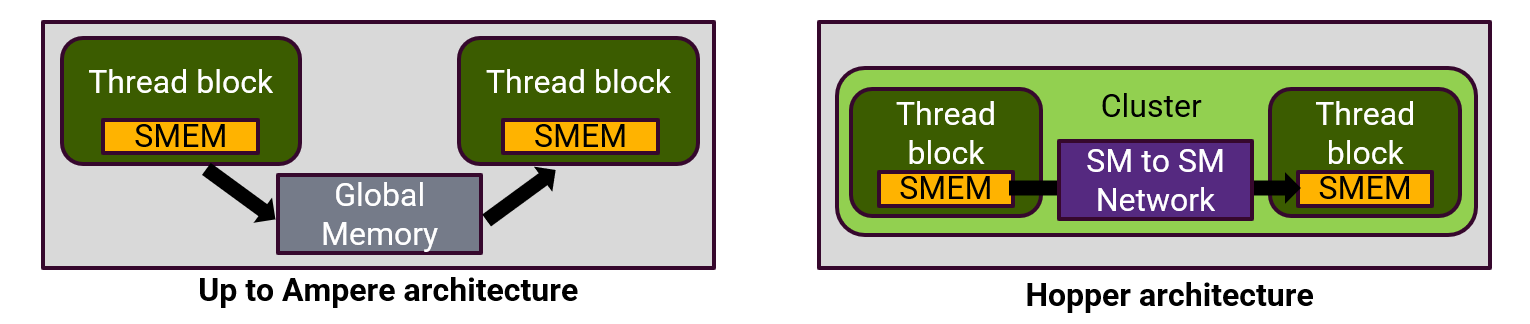
5. 하지만 threadblock 내에서는 thread간 즉 wrap사이의 memory 공유가 가능했는데 이를 M2NDP에서는 NDP unit 안에 on-chip scratchpad memory를 추가해 µthread 간 data 공유를 할 수 있게 만들었음
6. NVIDIA’s Hopper GPU의 경우 TB(Thread Block)간 shared memory 에서 data 공유가 가능하게 만드는 기술이 들어감 하지만 해당 기술을 사용할 경우 thread block의 granularity가 더 coarser해져 resource underutilization 발생함
7. DRAM(LPDDR의 경우 32B, DDR5의 경우 64B)의 Bandwidth를 fully utilize 하기 위해 32B granularity로 match되어있음
NDP Unit Microarchitecture

- µthread generator에서 µthread 를 spawn하고 µthread slot에 allocating 되는 구조임
- virtual address를 통해 access하고 on-chip TLB, DRAM-TLB, ATS를 통해 Translation 되는 구조 Local memory의 data에 access 하고 싶은 경우 direct하게 access 하는 protocol이 없기 때문에 page fault를 이용해서 간접적으로 접근함
DRAM-TLB의 경우 아래 논문을 참고하면 좋을 것 같다.
https://dl.acm.org/doi/10.1145/3309710
DUCATI: High-performance Address Translation by Extending TLB Reach of GPU-accelerated Systems: ACM Transactions on Architecture
Conventional on-chip TLB hierarchies are unable to fully cover the growing application working-set sizes. To make things worse, Last-Level TLB (LLT) misses require multiple accesses to the page table even with the use of page walk caches. Consequently, ...
dl.acm.org
- 추가적으로 Cache coherence를 보장해 주기 위해 GPU의 cache hierarchy를 사용한다. 필자가 이해한 바로는 atomic operation을 위해 SM 외부에 존재하는 L2 Cache에서 정보를 쓰는 방식으로 진행하는 것 같다.